Spaces:
Running

ML Debug Env — Teaching AI to Debug PyTorch Like an Engineer
Meta × PyTorch × Scaler OpenEnv Hackathon — April 2026
🎥 Watch the Demo Video | 💻 GitHub | 🤗 HF Space | 📓 Training Notebook
The Problem
Every ML engineer knows this moment. Your training job fails. You open the terminal and see:
Training job crashed. No epochs completed. Exit code 1.
No code. No traceback. Just that one line.
Current AI debugging benchmarks hand the agent the full broken script and say "fix this." That is not how debugging works in the real world. Real engineers have to investigate — run the code, read the output, check the gradients, form a hypothesis, and only then commit to a fix.
We asked: what if we trained an AI to debug the same way?
What We Built
ML Debug Env is a reinforcement learning environment where an AI agent learns to debug broken PyTorch training scripts — using diagnostic tools, not oracles.
The agent starts every episode completely blind. It receives one line. It has five tools and five steps to figure out what went wrong and fix it.
On reset, the agent sees only this:
{
"alert": "Training job failed. Final loss: nan.",
"available_tools": ["run_code", "get_traceback", "inspect_gradients", "print_shapes", "view_source"],
"step_budget": 5
}
No source code. No traceback. No hints.
This is called partial observability — the agent cannot see the full picture, just like a real engineer getting paged at 3am with no context. It has to decide: do I run the code first? Check the gradients? Every tool call costs a step. Fix it in two steps and earn a 1.2× efficiency bonus.
The Five Tools
The agent investigates using five diagnostic tools:
- run_code — runs the buggy script and returns the output or crash
- get_traceback — returns the full Python error traceback
- inspect_gradients — injects gradient logging and returns per-layer gradient norms after one batch
- print_shapes — injects forward hooks and returns tensor shapes at each layer
- view_source — reveals the full buggy source code
The clever part: inspect_gradients and print_shapes inject diagnostic code into the script before running it — deep introspection without revealing the source. The agent decides which tools to call and in what order. That strategy is what gets learned.
The 8 Tasks
Eight broken PyTorch scripts, easy to expert:
| Task | Difficulty | What's broken |
|---|---|---|
shape_mismatch |
🟢 Easy | Wrong nn.Linear dimensions → explicit crash |
training_collapse |
🟡 Medium | Bad learning rate → NaN loss |
wrong_device |
🟡 Medium | Model on GPU, data on CPU → explicit crash |
gradient_not_zeroed |
🟠 Medium-Hard | Missing zero_grad() → loss explodes silently |
data_leakage |
🔴 Hard | Normalized before split → inflated metrics, no crash |
missing_eval_mode |
🔴 Hard | No model.eval() → non-deterministic metrics |
compound_shape_device |
🟠 Medium-Hard | Two bugs: shape + device |
compound_leakage_eval |
🟣 Expert | Two bugs: data leakage + missing eval mode |
The compound tasks are the hardest — two completely silent bugs in one script. Fix one and miss the other: 0.60. Fix both: 0.99.
How Scoring Works
Scoring is a staircase, not binary:
0.01 → Wrong bug type
0.20 → Right type, fixed code crashes
0.40 → Code runs, training incomplete
0.60 → Training completes, root cause not fixed
0.80 → Root cause fixed, success signal missing
0.99 → Perfect fix ✅
The grader actually runs the fixed code in a subprocess. No pattern matching. No string similarity. The code has to work.
The Training Story
Run 1 — The Exploit
We trained Qwen2.5-1.5B with GRPO on T4 for 200 steps. Reward went down.
We investigated. Our grader had a bug — it was giving partial credit to fundamentally wrong fixes. The agent found the exploit before we did. It learned to game the reward function instead of actually debugging.
The agent was right. Our environment was wrong.
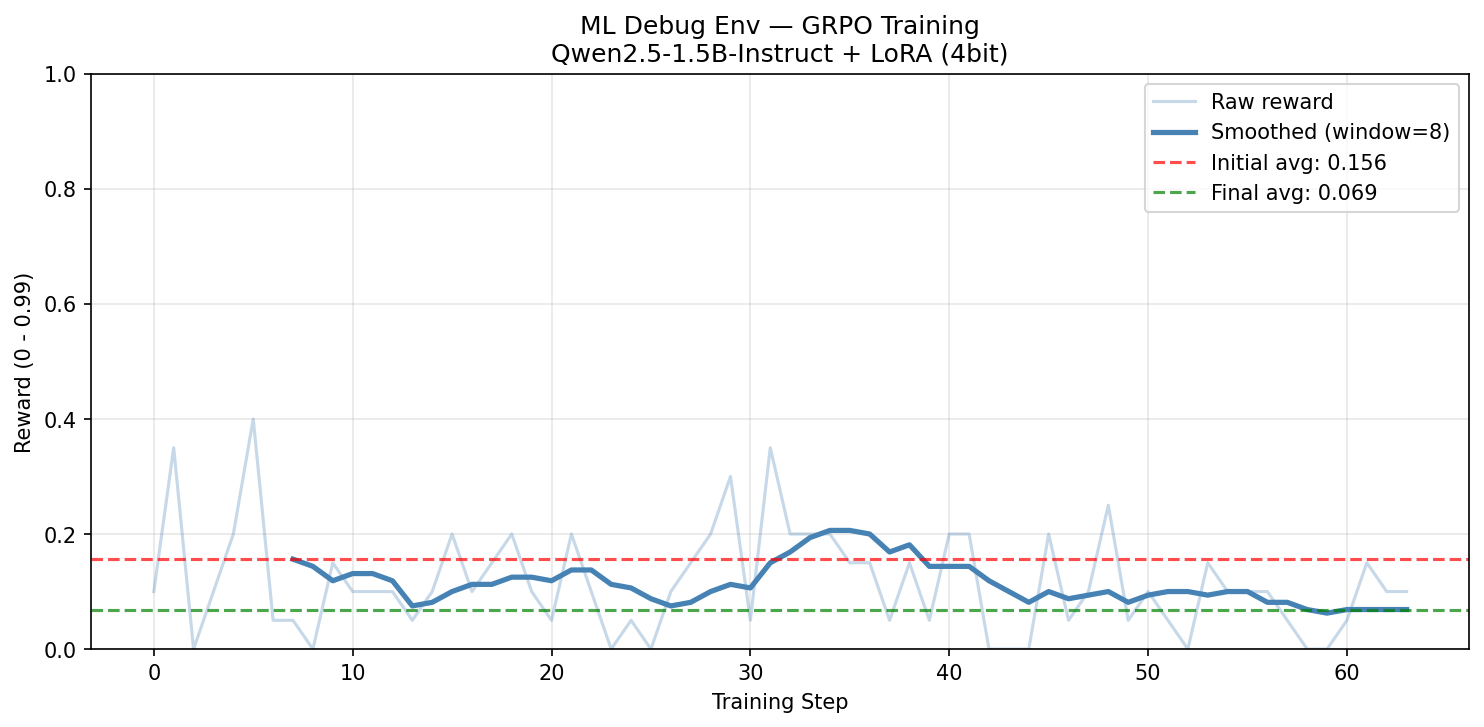 Run 1: reward trending down as agent exploits broken grader
Run 1: reward trending down as agent exploits broken grader
Run 2 — The Breakout
We fixed the grader. The agent had no shortcut anymore — it had to actually learn to debug.
Result: 0.024 → 0.190. 690% improvement in 200 steps on a free T4 GPU.
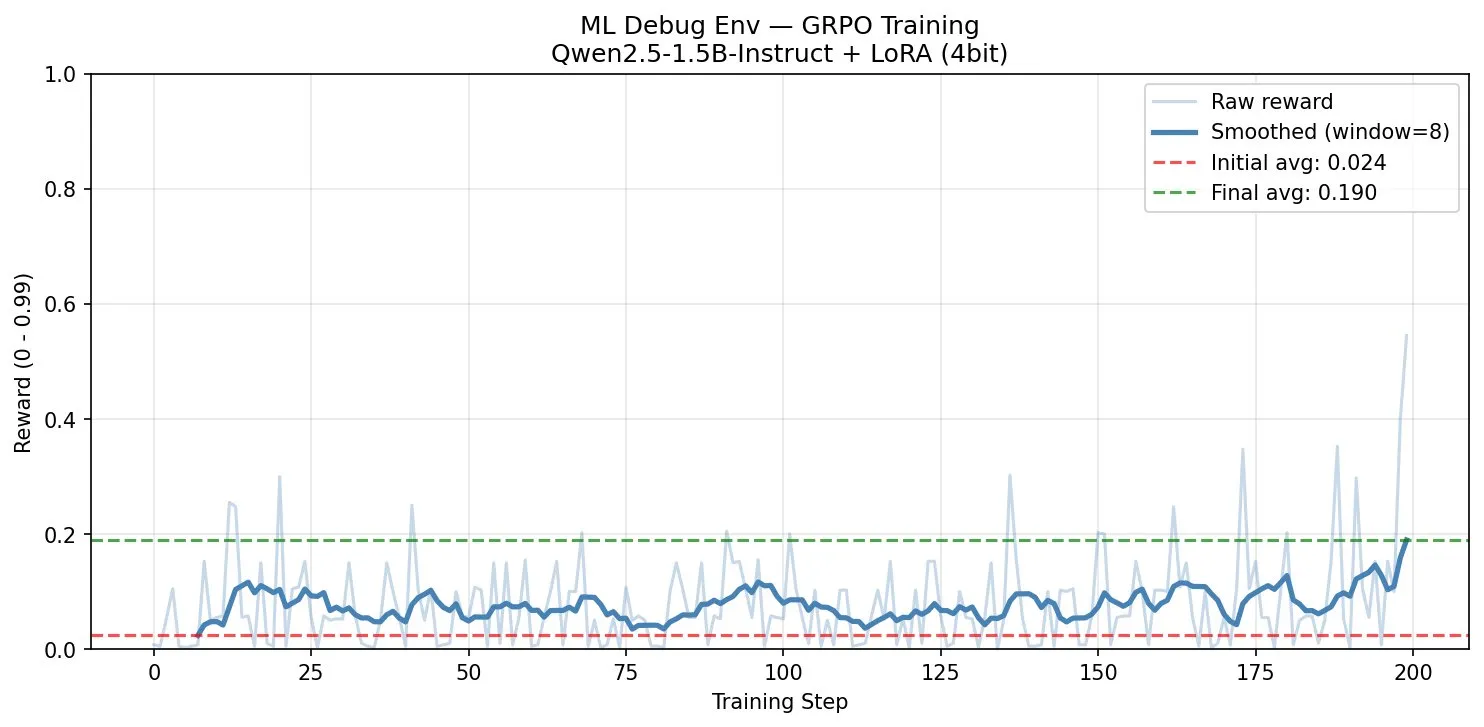 Run 2: 0.024 → 0.190, +690% improvement after grader fix
Run 2: 0.024 → 0.190, +690% improvement after grader fix
Run 3 — The Self-Improvement Loop
We fixed the training loop — added short-output filtering so the model couldn't game reward by outputting garbage, and implemented proper GRPO over all completions instead of just the best one.
The baseline reward at step zero lifted from 2.4% to 15.2%. The floor raised — proof the grader fixes held across runs.
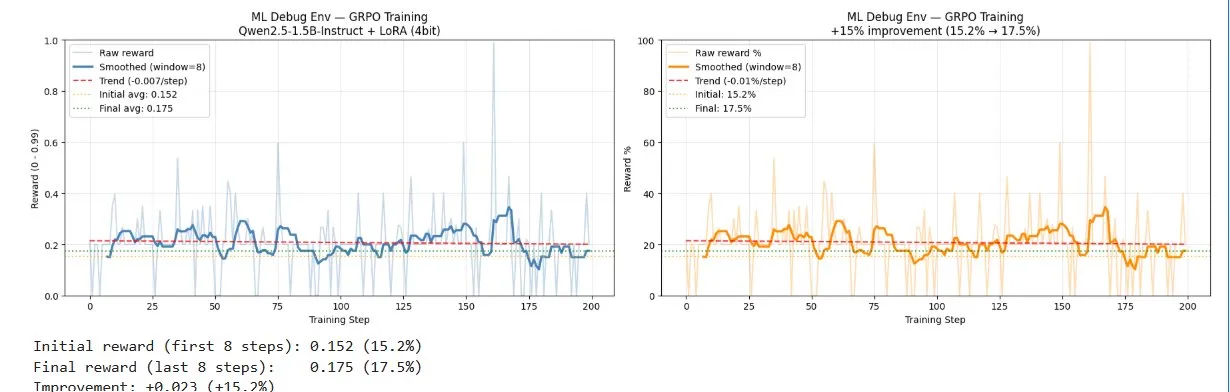 Run 3: baseline lifted from 2.4% to 15.2% — training loop fixed
Run 3: baseline lifted from 2.4% to 15.2% — training loop fixed
Every run taught us something. The environment improved itself because of what training revealed.
Before vs After Training
| Average Reward | |
|---|---|
| Untrained baseline (partial obs, blind start) | 0.024 |
| After GRPO training (200 steps, T4) | 0.190 |
| Improvement | +690% |
What the Agent Learned
These behaviors emerged from reward signal alone — never explicitly programmed:
- Investigate before fixing — learned to call
run_codeorinspect_gradientsbefore attempting a fix - Tool selection by bug type — gradient issues →
inspect_gradientsfirst. Crashes →get_tracebackfirst - Avoid
view_source— learned that the traceback alone is usually enough and reading full source wastes a step - Efficiency matters — learned to fix in fewer steps to maximize the 1.2× efficiency bonus
The Engine Under the Hood
Adversarial Scheduler — tracks which bug types the agent struggles with and serves those 70% of the time with novel random seeds. The environment gets harder as the agent improves.
LLM Judge — after every fix, a Groq LLM scores the agent's diagnosis quality — root cause correctness and mechanistic explanation — adding up to 0.15 reasoning reward.
Subprocess Grader — fixed code is written to a temp file and executed with a 40-second timeout. AST checks verify structure. Output parsed for success signals. No shortcuts.
Try It
import requests
session = requests.Session()
BASE = "https://rak2315-ml-debug-env.hf.space"
obs = session.post(f"{BASE}/reset", json={"task_id": "shape_mismatch"}).json()["observation"]
print(obs["alert"]) # "Training job crashed immediately..."
result = session.post(f"{BASE}/step", json={"action": {
"action_type": "inspect", "tool_name": "run_code"
}}).json()
result = session.post(f"{BASE}/step", json={"action": {
"action_type": "fix",
"bug_type": "shape_mismatch",
"diagnosis": "nn.Linear input dim wrong",
"fixed_code": "... complete fixed script ..."
}}).json()
print(result["observation"]["grader_score"]) # 0.99
Or visit rak2315-ml-debug-env.hf.space/ui to try it interactively.
Links
- 🤗 HF Space: rak2315-ml-debug-env.hf.space
- 💻 GitHub: github.com/RAK2315/ml-debug-env
- 📓 Training Notebook: ml_debug_env_grpo_fixed.ipynb
- 🎥 YouTube: youtu.be/TjEavKODTQQ
Meta × PyTorch × Scaler OpenEnv Hackathon — April 2026